Для локальной установки OpenSource моделей Llama и других можно использовать бесплатный продукт Ollama, данный продукт работает как веб-сервер, предоставляя возможность подключаться к языковым моделям через API интерфейс. Продукт «База знаний + ИИ» работает с Ollama также, как и с нейросетью GigaChat.
Для начала работы с Ollama скачайте дистрибутив продукта для вашей операционной системы с сайта https://ollama.com/download и выполните установку продукта.
После завершения установки Ollama проверьте его доступность в браузере введя http://localhost:11434 При корректной установке должна появиться надпись «Ollama is running».
В настройках продукта можно изменить порт 11434 на другое значение. При установке Ollama в Windows модели будут загружаться в каталог по умолчанию C:\Users\<пользователь>\.ollama Для Ubuntu это может быть каталог /var/snap/ollama или /usr/share/ollama. При необходимости можно изменить этот каталог на другое значение. Для этого перед загрузкой моделей в командной строке Windows выполните команду setx OLLAMA_MODELS «путь к каталогу»
Загрузка моделей выполняется из командной строки. Некоторый список моделей, доступных в Ollama, можно найти на странице сайта https://ollama.com/search Для загрузки и бесплатного использования доступны, например, такие модели:
- OpenSource Llama версий 3.2 и 3.3;
- Gemma от корпорации Google;
- Qwen2.5 от китайской Alibaba;
- DeepSeek (упрощенные версии);
- а также десятки других моделей.
Для загрузки модели Llama3.2 используйте команду ollama pull llama3.2, для загрузки модели Gemma2 используйте команду ollama pull gemma2 Эти модели занимают не очень много места (около 5 GB) на диске, другие модели могут потребовать 100 и более гигабайт свободного пространства. Обратите внимание — для нормальной работы модели она должна полностью помещаться в оперативную память вашего сервера, имейте это ввиду при планировании работы.
При загрузке моделей можно указать модель с каким количеством параметров вам нужна. Например, для модели llama3.2 возможны варианты 1b и 3b, для модели deepseek-r1 возможны варианты 1.5b, 7b, 8b, 14b, 32b, 70b, 671b. Эти варианты обозначают количество миллиардов параметров, на которых тренировалась модель. Чем больше значение, тем более сложная модель и больше ресурсов сервера она будет требовать. Указать конкретный вариант модели можно в команде при загрузки модели, например для модели gemma2 с 9 миллиардами параметров используйте команду ollama pull gemma2:9b
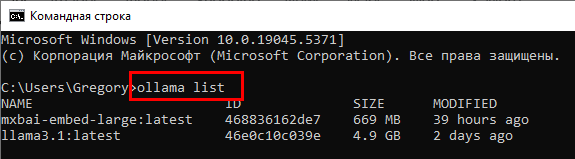
Посмотреть, какие модели успешно загружены можно командой ollama list пример вывода приведен на скриншете ниже. Удалить модель можно командой ollama rm <имя модели>
Важно: Для выполнения индексирования базы знаний (или векторизации в терминах ИИ) скачайте модель mxbai-embed-large командой ollama pull mxbai-embed-large или другую, предназначенную именно для векторизации данных (эмбеддинга).
Для удобного мониторинга загрузки оборудования при работе ollama можно использовать приложение nvtop, а для видеокарт Nvidea можно использовать приложение nvidia-smi, в Windows его можно запустить командой C:\Windows\System32\nvidia-smi.exe
Скорость ответа модели очень сильно зависит от её сложности, а также производительности вашего оборудования, скорость ответа может быть меньше одной секунды, а может составлять и минуты на медленных серверах.
Внимание! Получите скидку 25% на GPU VPS сервер https://firstvds.ru (можно перейти по ссылке или ввести промо-код: 648365752)
Другой вариант — использовать сервера Immers.Cloud для обработки ИИ с высокопроизводительными графическими картами (GPU) — immers.cloud
При работе с «База знаний + ИИ» вы можете использовать нейросеть GigaChat от Сбер. Описание её настройки приведено на этой странице
Смотрите также: