Продукт «База знаний + ИИ» позволяет работать с различным моделями нейросетей. В текущей версии поддерживается два основных типа моделей — модель GigaChat от Сбера и OpenSource модели на базе сервиса Ollama.
Для настройки моделей необходимо использовать справочник «Модели GPT», открыть его можно через форму «Настройки ИИ».
В справочнике моделей нейросетей можно указать вид и тип нейросети, настроить учет токенов (если требуется), а также других параметров.
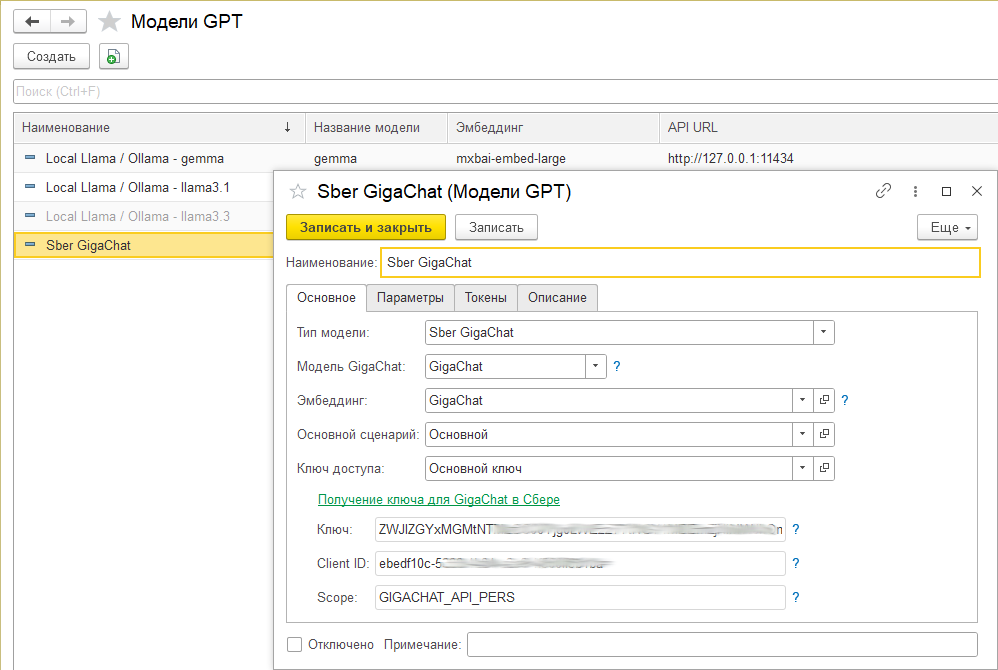
В форме справочника «Модели GPT» есть набор параметров. При добавлении элемента в справочник нужно указать тип модели – «Sber GigaChat» или «Local Llama / Ollama». При выборе типа модели «Sber GigaChat» необходимо заполнить дополнительные поля — поле с видом модели, где можно выбрать вариант «GigaChat», «GigaChat-Pro» или «GigaChat-Max».
Подключение к Сбер API производится через ключ доступа, который указывается в поле «Ключ доступа». Подробнее о подключении к API GigaChat рассказано здесь. В частности, вам нужно будет получить ключ, а также значение Client ID и Scope.
На закладке «Параметры» можно нужно указать путь к расположению точки входа для запросов к API, для модели GigaChat значение заполняется по умолчанию (на текущий момент это https://gigachat.devices.sberbank.ru/api/v1), а для моделей использующих Ollama нужно указать собственный сервер и порт для доступа к API (по умолчанию http://127.0.0.1:11434).
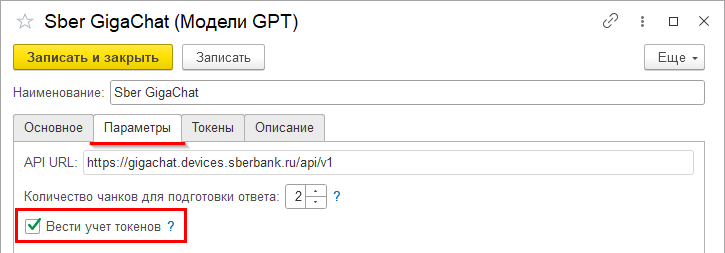
Если для модели требуется учет расходов токенов, то необходимо включить флажок «Вести учет токенов» как показано на рисунке ниже.
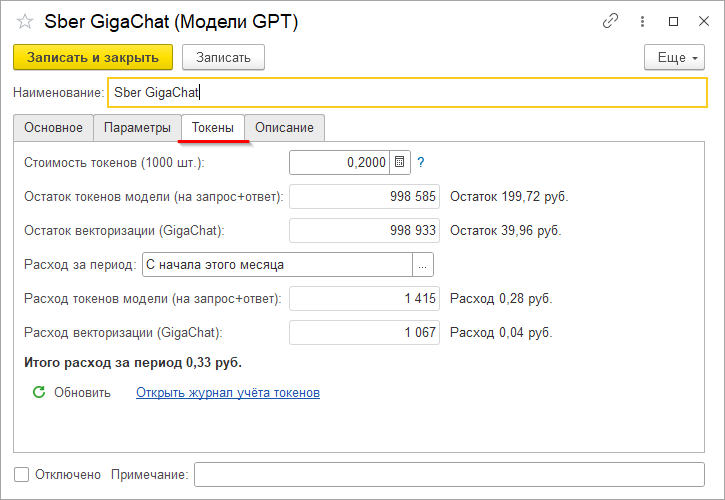
При включении учета токенов становится доступной закладка «Токены», где можно посмотреть остаток токенов и их расход за выбранный период.
Стоимость 1000 токенов можно указать на закладке «Токены», а стоимость токенов для векторизации в настройках справочника «Модели эмбеддинга» (см. далее в следующем разделе).
Посмотреть подробную информацию о расходе и поступлении (покупке) токенов можно через журнал учета токенов. Поступление токенов оформляется записью в журнале с указанием модели с количеством поступивших токенов.
Модели эмбеддинга
Для учета операций индексации данных (или эмбеддинга в терминах нейросетей) используется другой справочник «Модели эмбеддинга». Данные модели позволяют разбить текст статьи базы данных на части (чанки данных) и преобразовать их в векторное представление. Векторное представление позволяет потом быстро найти подходящую часть базы знаний и использовать в запросах (промтах) к нейросети.
В настройках модели GPT (см. прдедыущий раздел) нужно указать ссылку на один из элементов модели эмбеддинга.
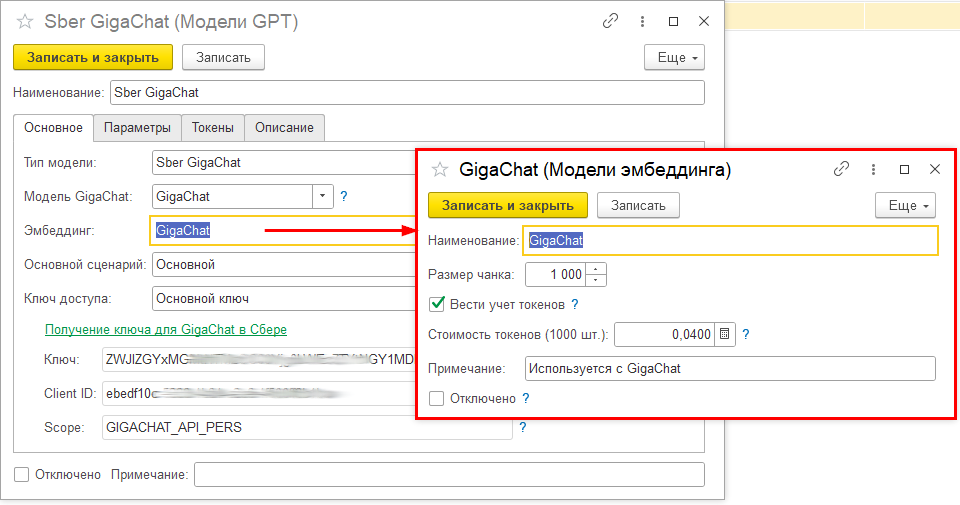
В справочнике «Модели эмбеддинга» можно включить учет токенов и указать стоимость за 1000 токенов, которая обычно отличается от стоимости токенов для обычных ответов нейросети.
Обратите внимание на параметр «Размер чанка». Чанк – это некоторая часть текста, которая подлежит векторизации для последующего поиска по базе данных. Рекомендуемое значение для большинства моделей 1000.
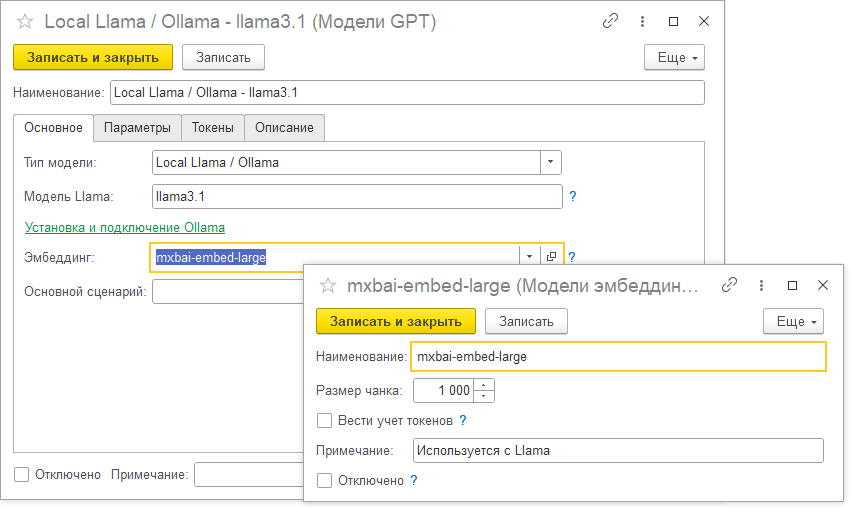
При использовании OpenSource моделей Ollama можно использовать одну модель эмбеддинга для разных нейросетевых моделей. Обычно используется модель «mxbai-embed-large». На рисунке ниже приведен пример настройки модели llama3.1 и модели для векторизации.
Обратите внимание на то, что форма для OpenSource моделей несколько отличается от формы для настройки модели GigaChat, в ней не ведется учет токенов, а также нет параметров для ключа доступа к API.
Сценарии запросов
Для каждой модели можно создать один или несколько сценариев запросов. Сценарии запросов позволяют уточнить запрос к нейросетевой модели, добавив в него уточняющие фразы.
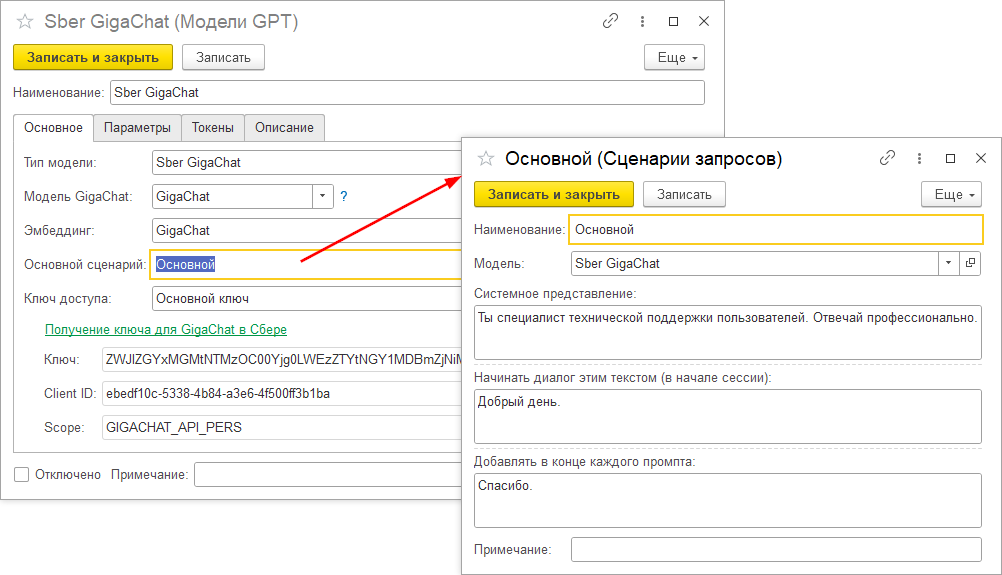
В сценарии запросов можно указать системное представление, которое помогает модели понять в каком стиле выдавать ответ. Например, можно написать о том, что модель должна давать ответ как специалист тех. поддержки, или давать ответ в дружеском или неформальном тоне.
Также в сценарии запроса можно указать фразу, которая будет автоматически добавляться перед началом каждого запроса и в конце запроса. Такие фразы немного изменяют качество и стиль ответов нейросети.
При формировании запросов к нейросети можно выбрать по какому сценарию будет выполняться запрос. По умолчанию выполнение запроса идет по основному сценарию, указанному в настройках модели.
Смотрите также: